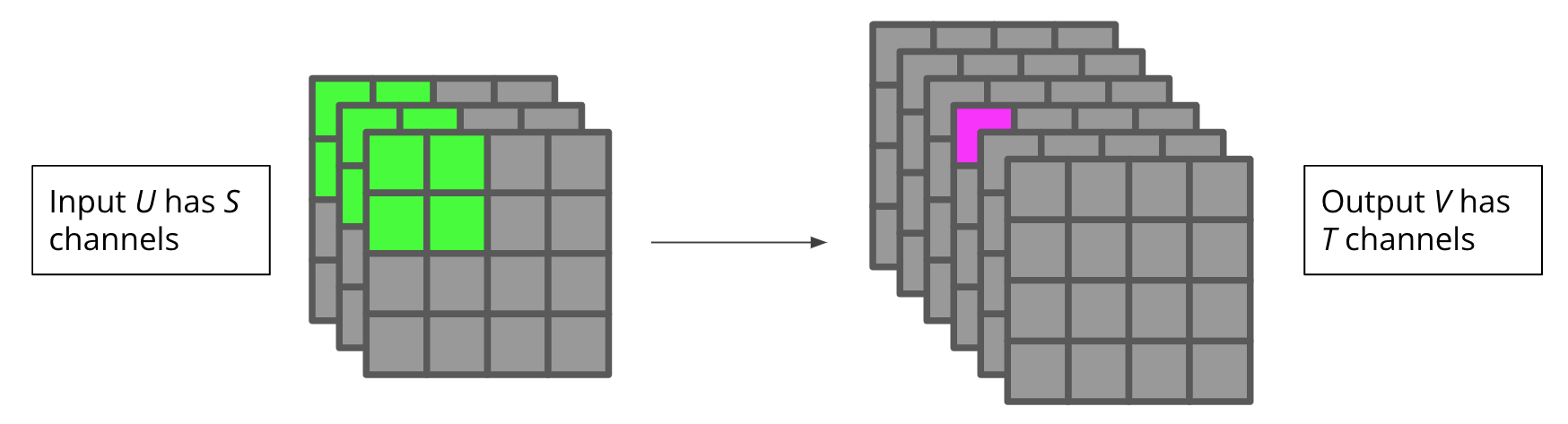
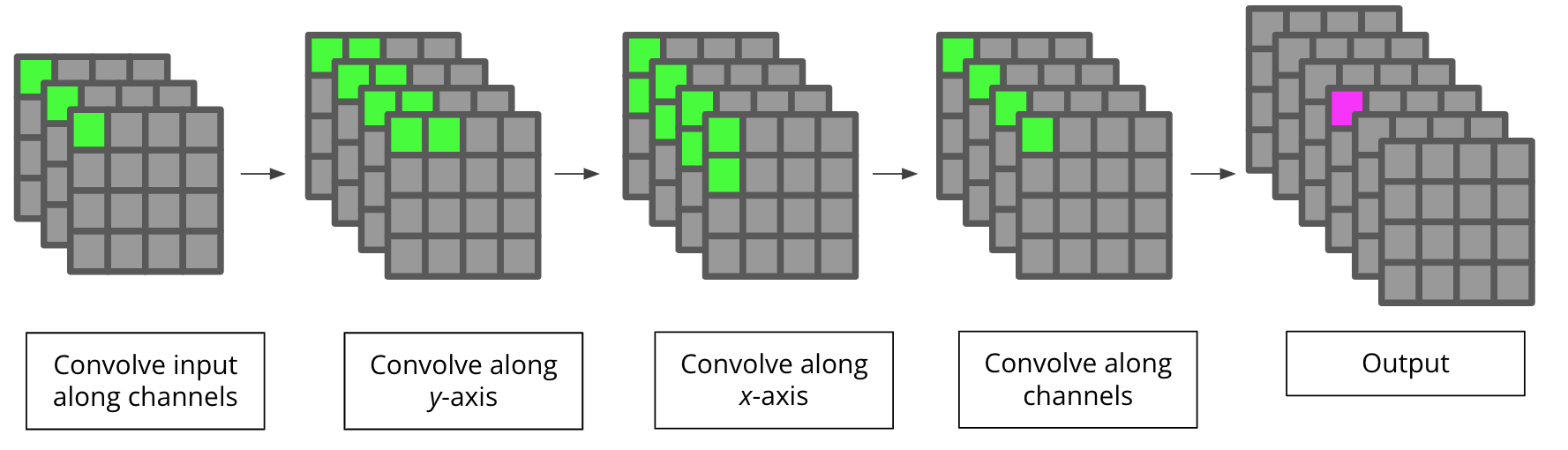
def decompose_kernel(weights, rank, cutoff=1e-8, max_iter=100, directory=None):
'''
Wrapper for cp_als. Takes convolution kernel, creates sptensor file, decomposes, and cleans up.
'''
shape = weights.shape
tensor = []
prods = [np.prod(shape[i:]) for i in range(len(shape))] + [1]
for i in range(prods[0]):
idx = ()
for d in prods[1:]:
n = i // d
idx += (n,)
i -= n * d
value = weights[idx]
if np.abs(value) > cutoff:
tensor.append(list(idx) + [value])
out = open('tensor_data.txt', 'w')
out.write('sptensor\n' + str(len(shape)) + '\n' + ' '.join(map(str, shape)) + '\n' + str(len(tensor)) + '\n')
for entry in tensor:
out.write(' '.join(map(str, entry)) + '\n')
out.close()
decomp = cp_als('./tensor_data.txt', rank, max_iter=max_iter, mem_limit_gb=MEM_LIMIT_GB)
if directory:
write_cp_decomp_dir(directory, decomp, True)
os.remove('tensor_data.txt')
return decomp
def factorized_conv(decomp, input_shape, strides, padding, bias, set_weights=True):
'''
Takes a decomposition of a convolutional kernel and returns a factorized layer
'''
rank = decomp.rank
n_dims = decomp.order - 2
factors = decomp.factors
weights = decomp.weights
input_layer = layers.Input(shape=input_shape)
x = layers.Conv1D(filters=factors[-2].shape[1], kernel_size=1, use_bias=False)(input_layer)
for i in range(n_dims):
permute = list(range(1, n_dims + 2))
d = permute.pop(i)
permute.insert(-1, d)
x = layers.Permute(tuple(permute))(x)
x = layers.Conv1D(filters=factors[i].shape[1],
kernel_size=factors[i].shape[0],
strides=strides[i],
padding=padding,
groups=rank,
use_bias=False)(x)
permute = list(range(1, n_dims + 2))
d = permute.pop(-2)
permute.insert(i, d)
x = layers.Permute(tuple(permute))(x)
x = layers.Conv1D(filters=factors[-1].shape[0], kernel_size=1, use_bias=True)(x)
fact_conv = models.Model(inputs=[input_layer], outputs=[x])
if set_weights:
fact_conv.layers[1].set_weights([np.expand_dims(factors[-2], axis=0)])
for i in range(n_dims):
fact_conv.layers[3 + 3 * i].set_weights([np.expand_dims(factors[i], axis=1)])
fact_conv.layers[-1].set_weights([np.expand_dims((factors[-1]*weights).T, axis=0), bias])
return fact_conv